Gene Discovery in ALS with Language Models
Prioritizing causal genes in ALS by integrating statistical genetics with word embeddings from biomedical literature.
🧬 Gene Prioritization in ALS with Language Models
Unsupervised ALS Gene Discovery from Biomedical Literature Using Static and Contextual Embeddings
📅 Research Period: Jul 2025 – Jul 2026 [currently in development]
🌐 GitHub: Gene discovery
This research is supported by a FAPESP undergraduate fellowship (grant link).
Overview
Amyotrophic Lateral Sclerosis (ALS) is a fatal and highly heterogeneous neurodegenerative disease, with dozens of genes implicated across different patient subtypes. While large-scale genetic studies have identified many associated loci, translating these signals into clear causal gene hypotheses remains a major challenge.
This project explores an alternative, fully unsupervised discovery paradigm: instead of relying solely on genetic data, we mine decades of biomedical literature to identify genes that are consistently discussed in functionally meaningful contexts related to ALS. By leveraging language models, we capture latent semantic signals that reflect biological relevance, even before formal genetic confirmation.
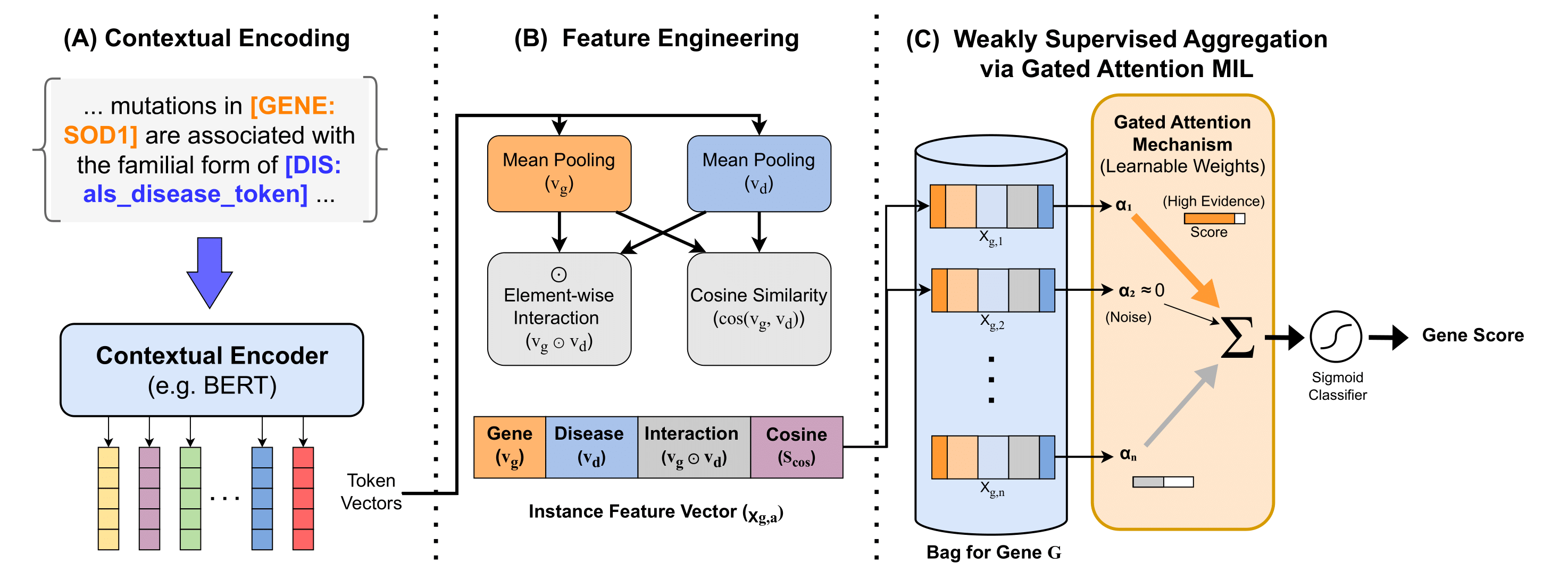
Method at a Glance

At a high level, the workflow consists of four stages:
- Literature collection: We construct a large ALS-focused corpus (~140k PubMed abstracts after preprocessing, spanning 1970–2026), with disease mentions normalized into a single token.
- Gene representation: Each gene is embedded into a vector space using both static models (Word2Vec, FastText) and contextual models (BERT, BioBERT, PubMedBERT, SciBERT).
- Evidence aggregation: For contextual models, gene–disease similarity is computed across multiple articles and summarized using a Multiple Instance Learning framework, capturing strong and recurrent disease-specific contexts.
- Gene ranking: Genes are ranked by their semantic proximity to ALS, producing a prioritized list of candidate genes.
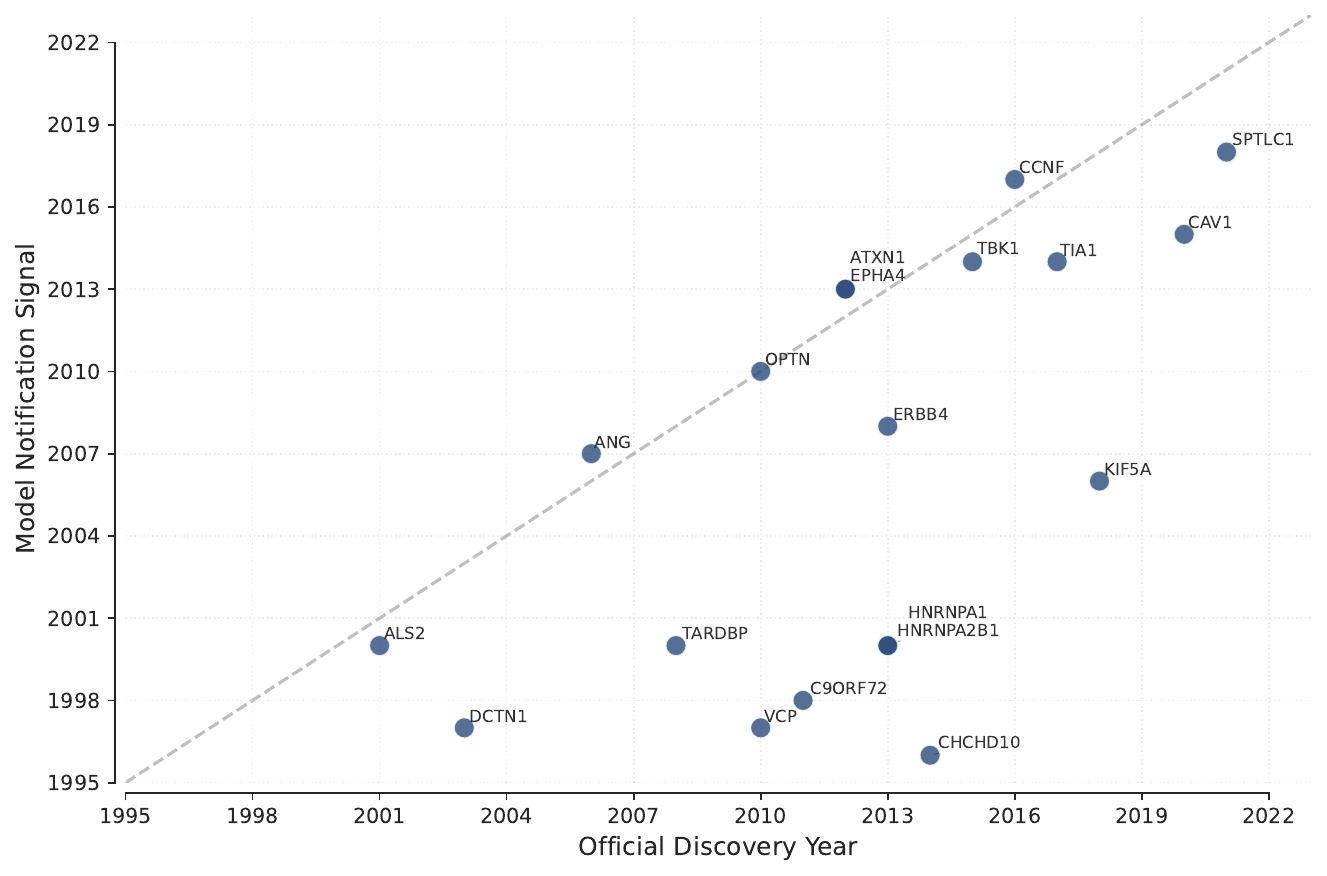
Temporal Discovery Signal
Beyond retrospective ranking, we evaluate whether literature-based embeddings can detect early discovery signals. Using a temporal analysis with static embeddings, the model successfully highlights genes years before their formal association with ALS appears in curated genetic studies, demonstrating the potential of language models as tools for hypothesis generation.
Authors
Ricardo Cerri – Assistant Professor, University of São Paulo (USP)